SpringBoot-Kafka Tutorial
Idempotent Consumer
What is idempotent consumer?
Idempotent consumer is a consumer that can process the same message multiple times without causing any side effects or data inconsistencies. Even if Kafka producer sends the same message multiple times, idempotent consumer will process it only once.
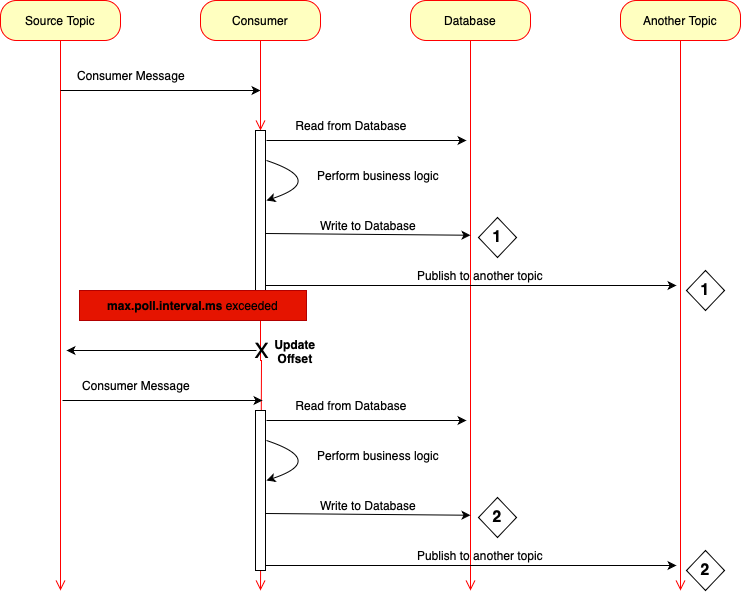
Consider the above diagram. Left side we can see the Kafka topic from which our Kafka consumer will consume messages. In previous lessons I called this topic as product created events topic. Kafka consumer is a second lifeline, and it is this consumer that we will try to make it important. Next I have Database Lifeline and it is a database that consumer application will work with. And then I have another topic lifeline. This is because Kafka Consumer can publish new message to another topic for another microservice to consume it.
So Kafka Consumer will consume a message, it will start processing this message. And depending on the business logic, it can do several different things. For example, it might need to connect to a database to fetch some data, and once it has all the information it needs, it will start executing its main business logic.
Then once it's done, it might need to write some information to a database and maybe even publish a new event to another Kafka topic. This might be a notification to another microservice that the job is done successfully. Now, while doing all of this business operations, it is possible that this code takes a very long time to complete, and because it took a longer time to complete, it exceeded the time configured with max poll interval in milliseconds Property.
Now this configuration property, it controls how much time Kafka Consumer has to process full messages before it should pull a new batch of messages from Kafka topic. If Kafka Consumer does not pull new messages from Kafka Broker longer than the time configured with this property, then Kafka Broker will assume that this consumer has failed, or it stopped and it will remove it from consumer group, and then it will trigger rebalance to reassign partitions to other consumers so that in other instance of Kafka, consumer can consume and process this message. If this happens, then this particular instance of consumer microservice, it will not be able to update partition offset. And this means that for Kafka Broker this message was not successfully consumed. So what Kafka Broker will do is it will deliver the same message to another instance of the same microservice, or even to the same instance. But when this instance rejoins the group. But either way, the same message will be consumed again, and then Kafka Consumer will start processing the same message for the second time.
It will again read from the database, start processing its main logic, and it will again write to the database, and at the end it will publish a new message to another topic. But this time it will be able to complete all the business logic in time and it will update partition offset. This will mean that this message is consumed successfully. But look what happened. We processed only one message, but there are two records in the database and we published two messages to another topic. And this is a big problem because if these are payment transactions, there was only one message with request to pay. But our Kafka consumer made two payments, so we need to prevent it.
Now another time when your consumer can receive duplicate message is when producer is not idempotent. If Kafka producer is not idempotent, it can produce duplicate messages. So your Kafka consumer should be able to avoid processing the same message multiple times. And one of the steps on the way to avoid situations like this is to make your Kafka consumer idempotent, meaning that it can receive the same message multiple times. But even if it does, it will process it only one time. Now, before I tell you how I'm going to avoid duplicate messages in this section of the course, please keep in mind that this will be only part of a solution. Ideally, to avoid duplicate messages in your application, you will use multiple techniques at the same time, and idempotent consumer is only part of the solution. Using idempotent consumer does help to avoid processing the same Kafka message twice, but it does not help. In all cases, they will still be edge cases when idempotent. Consumer alone is not enough. And another technique that you might want to use to avoid processing the same message twice is to make your Kafka producer idempotent as well.
Because that important producer helps you to prevent sending duplicate messages to Kafka Consumer making producer and consumer idempotent is a good combination. If you want to prevent processing this same Kafka message twice, and additionally to making producer and consumer idempotent, you will also want to use transactions in your application because transactions they help us group multiple message and database operations together so that they either all succeed or they all fail and they are all aborted.
If you use transactions and your application throws exception, then all database changes and all published messages, they are aborted and your microservice. It can retry the aborted operation from a clean state. And this also helps us to avoid duplicate writes to database and consuming duplicate messages from Kafka topic.
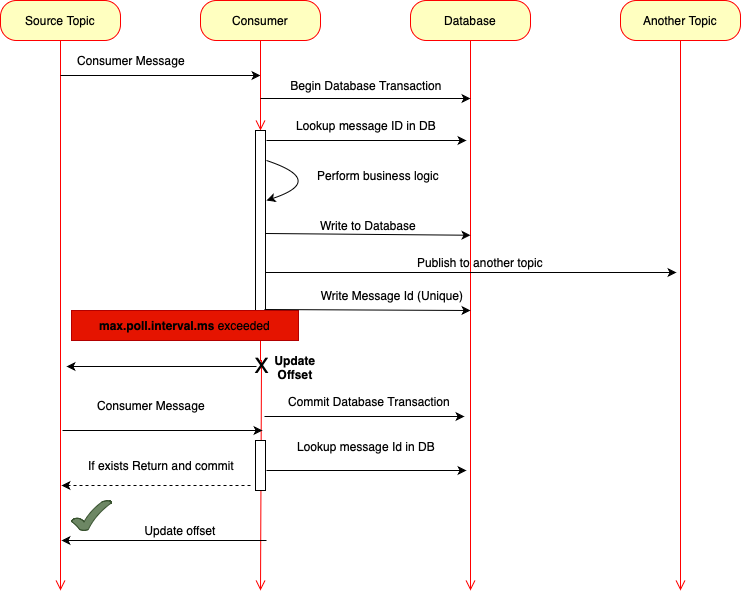
Now, depending on the business logic in your application, none of these techniques, if used alone, guarantee that there will be no duplicate processing of a message. Ideally, you want to use a combination of multiple techniques, and in this section of the course I will introduce you to one of these techniques. I'll use this diagram to show you how I'm going to update Kafka consumer to make it idempotent. So once there is a new message, consumer will consume this message. And because we will configure transaction support for this application, the code in this method it will execute within a transaction. So a new transaction will start our Kafka handler method. It will start processing this message. But the very first thing it will do it will check if this message was not processed earlier. And to do that we will look up on the database table. If a unique ID of this message is there, we will assign each Kafka message its own unique ID.
Once Kafka consumer consumes the message, it will first check database to see if message with this message ID was not processed earlier. If message was processed earlier, we will simply return from this method and transaction will complete. But if this message is a new message, then we can perform our business logic, maybe write results back to a database table, and maybe publish event to another Kafka topic. And then at the end we will write unique ID of this Kafka message to a database table. And this will help us remember that this message was processed successfully. If maximum poll interval exceeds, then partition offset will not be committed and Kafka Broker will remove this instance of consumer microservice from consumer group. It will do rebalancing and once that is done, the same message will be consumed again by either another instance of this microservice or by the same instance, but when it rejoins consumer group again. But even though this consumer application was removed from consumer group, the execution of our Java code will continue because there were no exception thrown in our Java code, the started at the beginning transaction.
It will successfully commit and all changes made to the database will be persisted. But because it failed to update partition offset for Kafka, this message was not consumed successfully. So it will deliver it again. And when this message is consumed again, our code will read unique message ID from message header. It will then look up message ID in the database. And if it does find that this message was already processed earlier, it will simply skip it. Because this is a duplicate message, it will not be processed again and our consumer will simply update the partition offset. And this time this message will be considered as consumed and will not be delivered again.
Wrtie Unique ID into message Header
Now will learn how to update products microservice to make it include a unique ID into message header. This message ID will then be read by consumer microservice to check if message with this ID was already processed or not. If message with provided ID was already processed, then consumer microservice will simply skip this message.
Now there are different ways to include a unique ID in a message. In products microservice which is working as a kafka producer we need to make changes in products service implementation class to send the uniqueID in message header.
If we want to work with message headers, we will need to use producer record class. So what we can do is we can create a producer record object outside of send method. And then we can pass it to a send method as a parameter. Now I can pass this producer record object as a parameter to send method. And because this producer record object gives me access to message headers, I can now add information to message header. I will add a new header with the key called message ID. And to generate a unique id, I will use Uuid.
Now, instead of generating a new unique ID value here, I could use product ID as a message ID and this is because to generate product id, I also used uuid. So it is also unique. And then I use product id as a message key because in Kafka message is a key value pair, but because Kafka message key could be a Json. For example, I want to show you how to use message key and message id separately. So I will use product ID as message key, and I will use message ID as another unique identifier that I'm including in message header.
This unique ID that I will store in a database to prevent processing and duplicate message. But if you don't want to introduce a second unique identifier, then it's fine. You can use product ID as unique identifier instead.
String productId = UUID.randomUUID().toString();
ProductCreatedEvent productCreatedEvent = new ProductCreatedEvent();
productCreatedEvent.setProductId(productId);
productCreatedEvent.setTitle(productRequest.getTitle());
productCreatedEvent.setPrice(productRequest.getPrice());
productCreatedEvent.setQuality(productRequest.getQuality());
LOGGER.info("Before publishing a product created event");
ProducerRecord<String, ProductCreatedEvent> record = new ProducerRecord<>(
"product-created-events-topic",
productId,
productCreatedEvent
);
record.headers().add("messageId", UUID.randomUUID().toString().getBytes());
SendResult<String, ProductCreatedEvent> result = kafkaTemplate.send(record).get();
LOGGER.info("****** Offset from the topic {} ", result.getRecordMetadata().offset());
LOGGER.info("****** Partition from the topic {} ", result.getRecordMetadata().partition());
LOGGER.info("****** Topic from the topic {} ", result.getRecordMetadata().topic());
Read Unique Id from Message Header
Now, we will work with consumer microservice and will make it read message ID from message header. I use email notification microservice as Kafka consumer. And inside of email notification microservice I will go to handler package and open product created event handler class and make below changes to read the unique ID from message header.
When Kafka Consumer consumes a message that is of product created event data type, this method will be triggered and it will receive product created event object as a method argument to read message header and to inject it into this method, we can add one more method argument. So right after product created event I will add comma and we'll add a new method argument. Which is going to be message ID, and we can actually use the same approach and inject message key into this method as well.
The product created event object will be read from message payload. Message ID and message key values will be read from message headers. And to tell Kafka which of these method arguments is payload and which of these method arguments is message key. Like below.
package com.navabitsolutions.email.notification.ms.handler;
import com.kafka.ws.core.ProductCreatedEvent;
import com.navabitsolutions.email.notification.ms.exceptions.NotRetryableException;
import com.navabitsolutions.email.notification.ms.exceptions.RetryableException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpMethod;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.kafka.annotation.KafkaHandler;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
import org.springframework.web.client.HttpServerErrorException;
import org.springframework.web.client.ResourceAccessException;
import org.springframework.web.client.RestTemplate;
@Component
@KafkaListener(topics="product-created-events-topic")
public class ProductCreatedEventHandler {
private final Logger LOGGER = LoggerFactory.getLogger(this.getClass());
@Autowired
private RestTemplate restTemplate;
@KafkaHandler
public void handle(@Payload ProductCreatedEvent productCreatedEvent,
@Header("messageId") String messageId,
@Header("messageKey") String messageKey) throws NotRetryableException {
LOGGER.info("Received a new event {}", productCreatedEvent.getTitle());
String requestUrl = "http://localhost:8082/response/200";
try {
ResponseEntity<String> response = restTemplate.exchange(requestUrl, HttpMethod.GET, null, String.class);
if (response.getStatusCode().value() == HttpStatus.OK.value()) {
LOGGER.info("Received response from the remote service {}", response.getBody());
}
} catch(ResourceAccessException ex) {
LOGGER.error(ex.getMessage());
throw new RetryableException(ex);
} catch (HttpServerErrorException ex) {
LOGGER.error(ex.getMessage());
throw new NotRetryableException(ex);
} catch (Exception ex) {
LOGGER.error(ex.getMessage());
throw new NotRetryableException(ex);
}
}
}
Database related dependencies
We made changes to our consumer microservice to read read unique ID from message headers, we can store this message ID in a database. Now, for development purposes, I almost always like to use in-memory or embedded database because it is quick to set up, and I don't need to install any additional database server on my computer. The database that I'm going to use is SQL database, and it can run embedded or as a server mode. It supports transactions, it supports encryption, and if needed it can be configured to store data on disk or in memory.
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
Configure Database connections
spring.datasource.username=sadakhat
spring.datasource.password=sadakhat
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.h2.console.enabled=true
Creating a JPA Entity
package com.navabitsolutions.email.notification.ms.entity;
import jakarta.persistence.*;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import java.io.Serializable;
@Entity
@Table(name = "processed-event")
@Setter
@Getter
@AllArgsConstructor
@NoArgsConstructor
public class ProcessedEventEntity implements Serializable {
@Id
@GeneratedValue
private long id;
@Column(nullable = false, unique = true)
private String messageId;
@Column(nullable = false)
private String productId;
}
Create JPA Repository
package com.navabitsolutions.email.notification.ms.repository;
import com.navabitsolutions.email.notification.ms.entity.ProcessedEventEntity;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ProcessedEventRepository extends JpaRepository<ProcessedEventEntity, Long> {
ProcessedEventEntity findByMessageId(String messageId);
}
Storing a unique Id into database table
Now, in email notification microservice we need to make changes to store the values into database. Refer below code for the same.
package com.navabitsolutions.email.notification.ms.handler;
import com.kafka.ws.core.ProductCreatedEvent;
import com.navabitsolutions.email.notification.ms.entity.ProcessedEventEntity;
import com.navabitsolutions.email.notification.ms.exceptions.NotRetryableException;
import com.navabitsolutions.email.notification.ms.exceptions.RetryableException;
import com.navabitsolutions.email.notification.ms.repository.ProcessedEventRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.dao.DataIntegrityViolationException;
import org.springframework.http.HttpMethod;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.kafka.annotation.KafkaHandler;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.client.HttpServerErrorException;
import org.springframework.web.client.ResourceAccessException;
import org.springframework.web.client.RestTemplate;
@Component
@KafkaListener(topics="product-created-events-topic")
public class ProductCreatedEventHandler {
private final Logger LOGGER = LoggerFactory.getLogger(this.getClass());
@Autowired
private RestTemplate restTemplate;
@Autowired
private ProcessedEventRepository repository;
@Transactional
@KafkaHandler
public void handle(@Payload ProductCreatedEvent productCreatedEvent,
@Header("messageId") String messageId,
@Header(KafkaHeaders.RECEIVED_KEY) String messageKey) throws NotRetryableException {
LOGGER.info("Received a new event {}", productCreatedEvent.getTitle());
ProcessedEventEntity existing = repository.findByMessageId(messageId);
if (existing!=null) {
LOGGER.warn("Found a duplicate messageId {}", existing.getMessageId());
return;
}
String requestUrl = "http://localhost:8082/response/200";
try {
ResponseEntity<String> response = restTemplate.exchange(requestUrl, HttpMethod.GET, null, String.class);
if (response.getStatusCode().value() == HttpStatus.OK.value()) {
LOGGER.info("Received response from the remote service {}", response.getBody());
}
} catch(ResourceAccessException ex) {
LOGGER.error(ex.getMessage());
throw new RetryableException(ex);
} catch (HttpServerErrorException ex) {
LOGGER.error(ex.getMessage());
throw new NotRetryableException(ex);
} catch (Exception ex) {
LOGGER.error(ex.getMessage());
throw new NotRetryableException(ex);
}
// Save unique message id into database
try {
repository.save(new ProcessedEventEntity(0, messageId, productCreatedEvent.getProductId()));
} catch (DataIntegrityViolationException e) {
throw new NotRetryableException(e);
}
}
}
Updated full source code is available in GitHub repository Kafka Consumer: Email Notification Microservice